
I am a first-year Ph.D. student in Computer Science at Northeastern University, advised by Prof. Zhenghao Liu. I received my M.S. degree in Computer Science from Northeastern University, where I was advised by Prof. Tong Xiao. My research focuses on large language models (LLMs), parametric knowledge, and foundation models.
Total page views: | Last edit: 2025-09-22 | Contact: pengcheng.neu@outlook.com
🔥 News
2026-01: 🎉 One paper accepted to ICLR 20262025-09: 🎉 One paper accepted to NeurIPS 20252025-09: 🎉 Three papers accepted to EMNLP 2025, with one selected for an oral presentation2025-08: 🎉 We released UltraRAG 2.0, an low-code framework for building complex RAG systems
2025-06: 🎉 One paper received the Highlight Poster Award 🏆 at YSSNLP 20252024-05: 🎉 One paper accepted to CCL 2024
📝 Publications
You can also find my articles on my Google Scholar profile. Note: * indicates equal contribution; \† indicates the corresponding author.
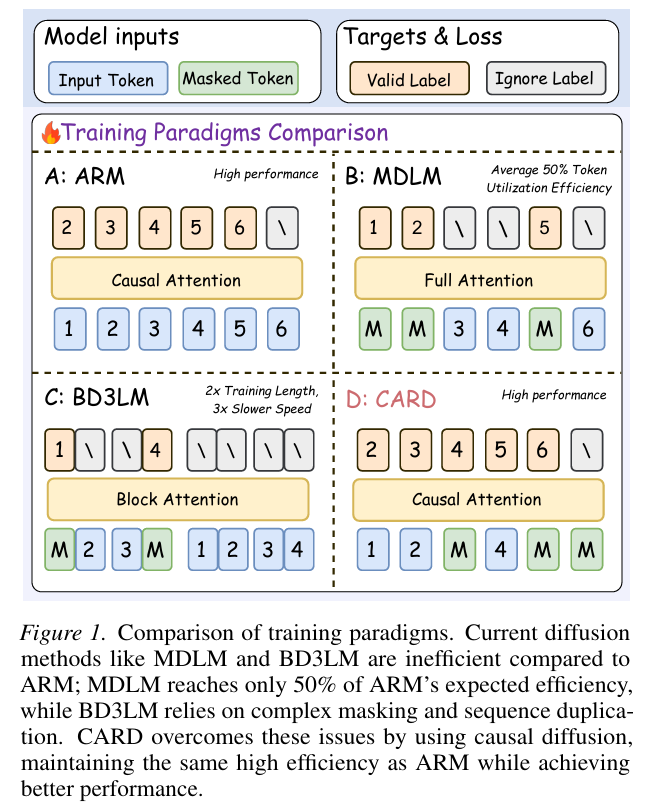
Causal Autoregressive Diffusion Language Model
Junhao Ruan, Bei Li, Yongjing Yin, Pengcheng Huang, Xin Chen, Jingang Wang, Xunliang Cai, Tong Xiao†, JingBo Zhu
- This paper introduces Causal Autoregressive Diffusion (CARD), a framework that unifies the training efficiency of autoregressive models with the high-throughput parallel inference of diffusion models by using a strictly causal attention mask and a dynamic decoding mechanism.
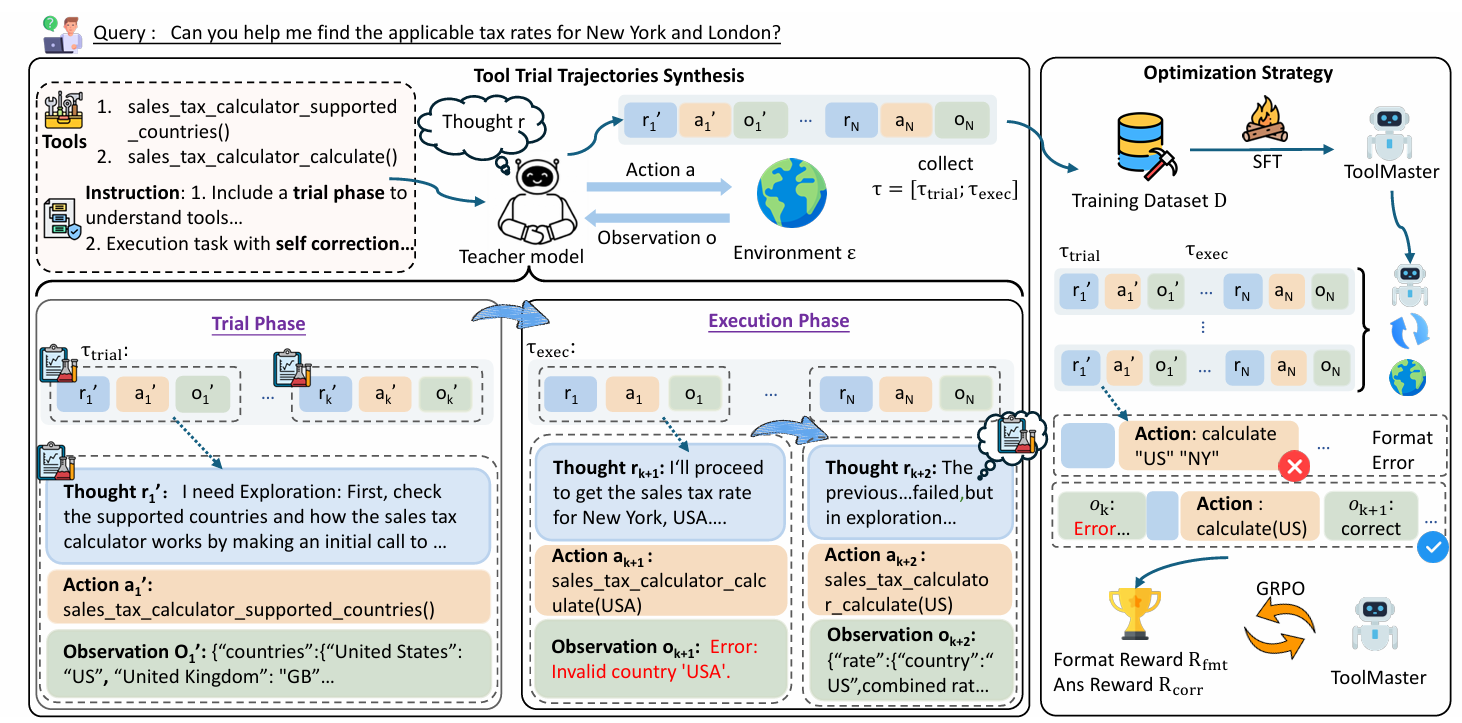
Teaching LLMs to Learn Tool Trialing and Execution through Environment Interaction
Xingjie Gao*, Pengcheng Huang*, Zhenghao Liu†, Yukun Yan, Shuo Wang, Zulong Chen, Chen Qian, Ge Yu, Yu Gu
- This paper proposes ToolMaster, a framework that enables LLMs to master complex tool usage by shifting from passive imitation of expert trajectories to an active trial-and-execution paradigm, where models learn to explore and self-correct through direct environment interaction.
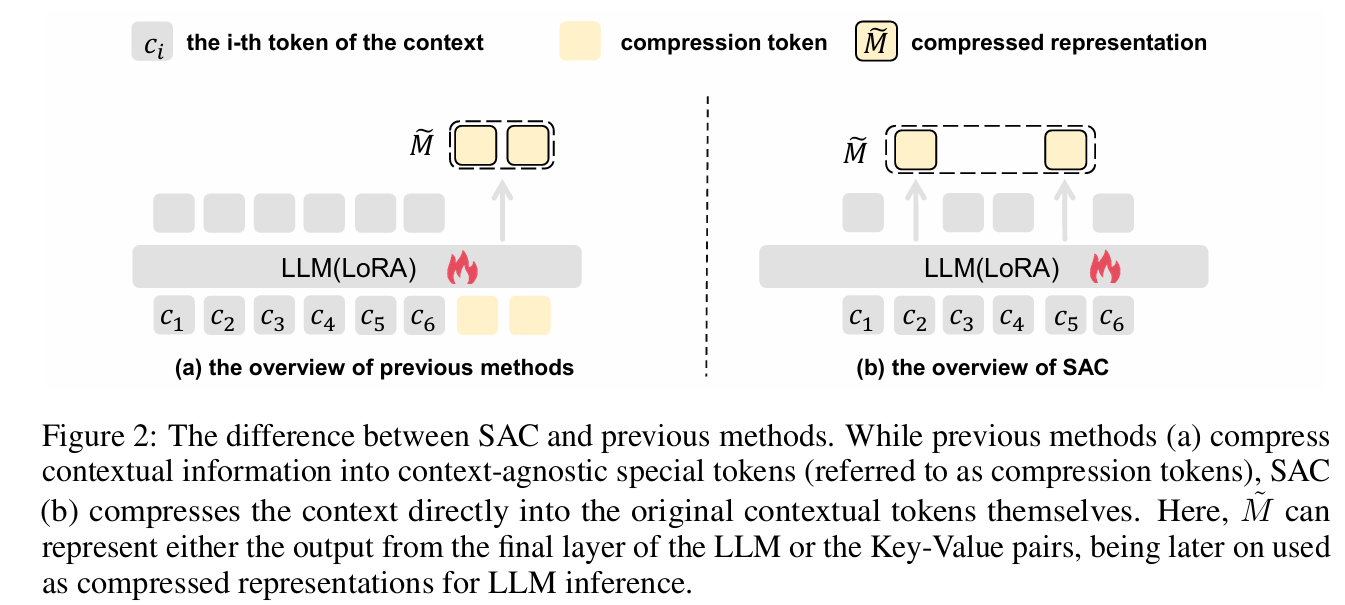
Autoencoding-free context compression for llms via contextual semantic anchors
Xin Liu, Runsong Zhao, Pengcheng Huang, Xinyu Liu, Junyi Xiao, Chunyang Xiao, Tong Xiao†, Shengxiang Gao, Zhengtao Yu, Jingbo Zhu
- This paper introduces Semantic-Anchor Compression (SAC), a novel method that achieves efficient context compression for LLMs by directly selecting and aggregating information into contextual “anchor tokens,” bypassing the limitations of traditional autoencoding-based training.
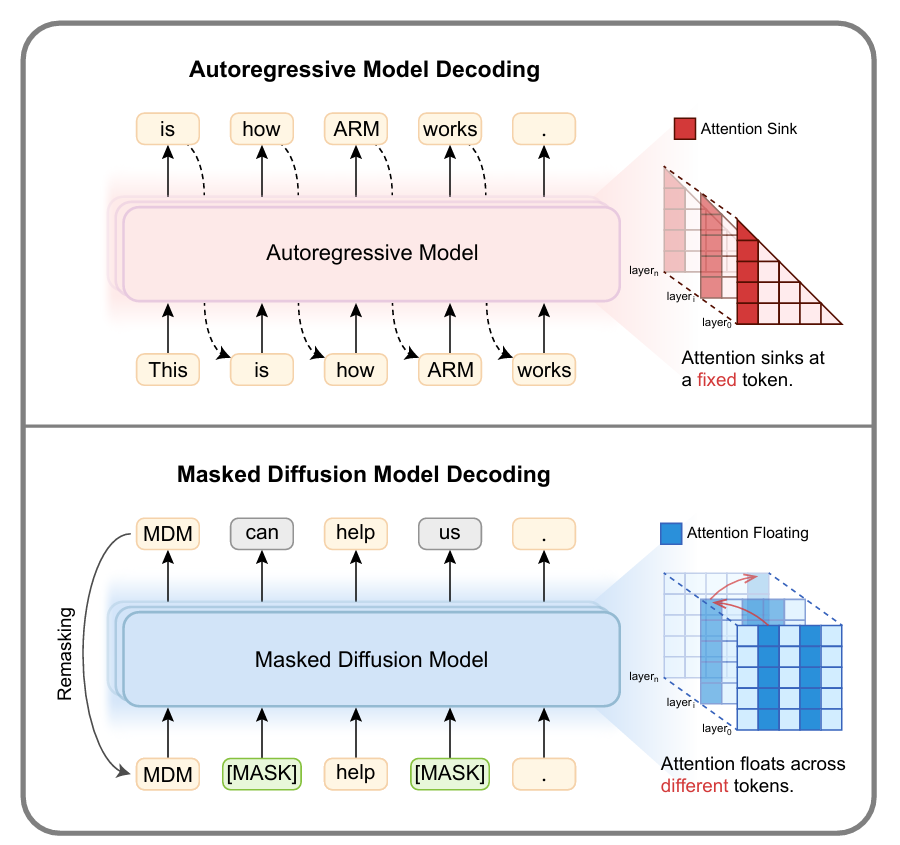
Revealing the Attention Floating Mechanism in Masked Diffusion Models
Xin Dai, Pengcheng Huang, Zhenghao Liu†, Shuo Wang, Yukun Yan, Chaojun Xiao, Yu Gu, Ge Yu, Maosong Sun
- This paper investigates the internal attention behaviors of Masked Diffusion Models (MDMs), identifying a unique “Attention Floating” mechanism where attention anchors dynamically shift across layers and denoising steps, which provides a mechanistic explanation for their superior in-context learning performance compared to autoregressive models.
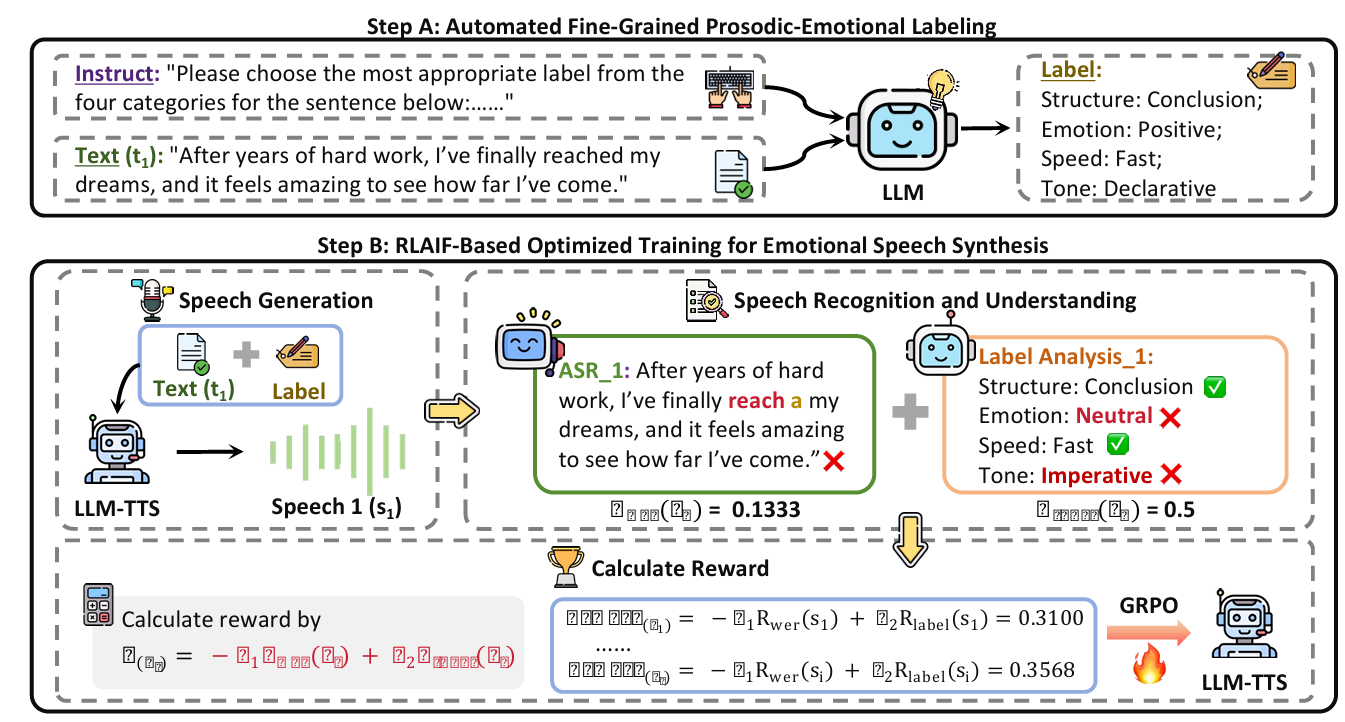
RLAIF-SPA: Optimizing LLM-based Emotional Speech Synthesis via RLAIF
Qing Yang, Zhenghao Liu†, Junxin Wang, Yangfan Du, Pengcheng Huang, Tong Xiao
- This paper proposes RLAIF-SPA, a framework that enhances the emotional expressiveness and prosodic naturalness of LLM-based speech synthesis by using Reinforcement Learning from AI Feedback to optimize semantic accuracy and fine-grained prosodic alignment.

ParamMute: Suppressing Knowledge-Critical FFNs for Faithful Retrieval-Augmented Generation
Pengcheng Huang, Zhenghao Liu†, Yukun Yan, Xiaoyuan Yi, Hao Chen, Zhiyuan Liu, Maosong Sun, Tong Xiao, Ge Yu, Chenyan Xiong
- This work presents ParamMute, a novel framework for enhancing the faithfulness of Retrieval-Augmented Generation. By identifying and suppressing unfaithfulness-associated feed-forward networks (FFNs), and incorporating a knowledge preference adaptation module, ParamMute effectively steers language models to better leverage retrieved evidence, paving the way for more reliable and trustworthy RAG systems.
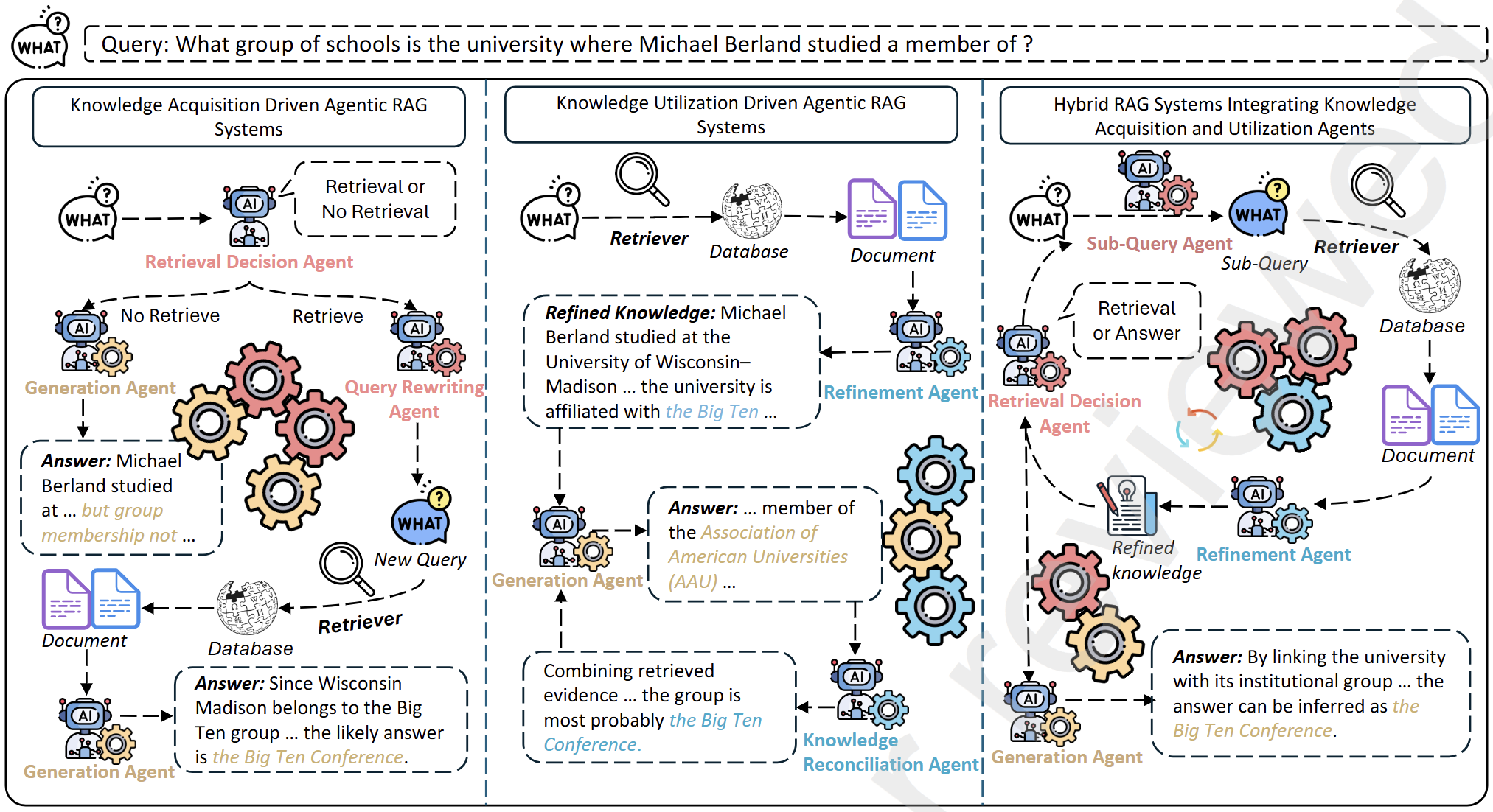
Knowledge Intensive Agents
Zhenghao Liu†, Pengcheng Huang, Zhipeng Xu, Xinze Li, Shuliang Liu, Chunyi Peng, Haidong Xin, Yukun Yan, Shuo Wang, Xu Han, Zhiyuan Liu, Maosong Sun, Yu Gu, Ge Yu
- This work provides a comprehensive overview of Retrieval-Augmented Generation from an agentic perspective, categorizing knowledge-intensive agents into acquisition and utilization roles, and highlighting future directions for joint optimization in multi-agent RAG systems.
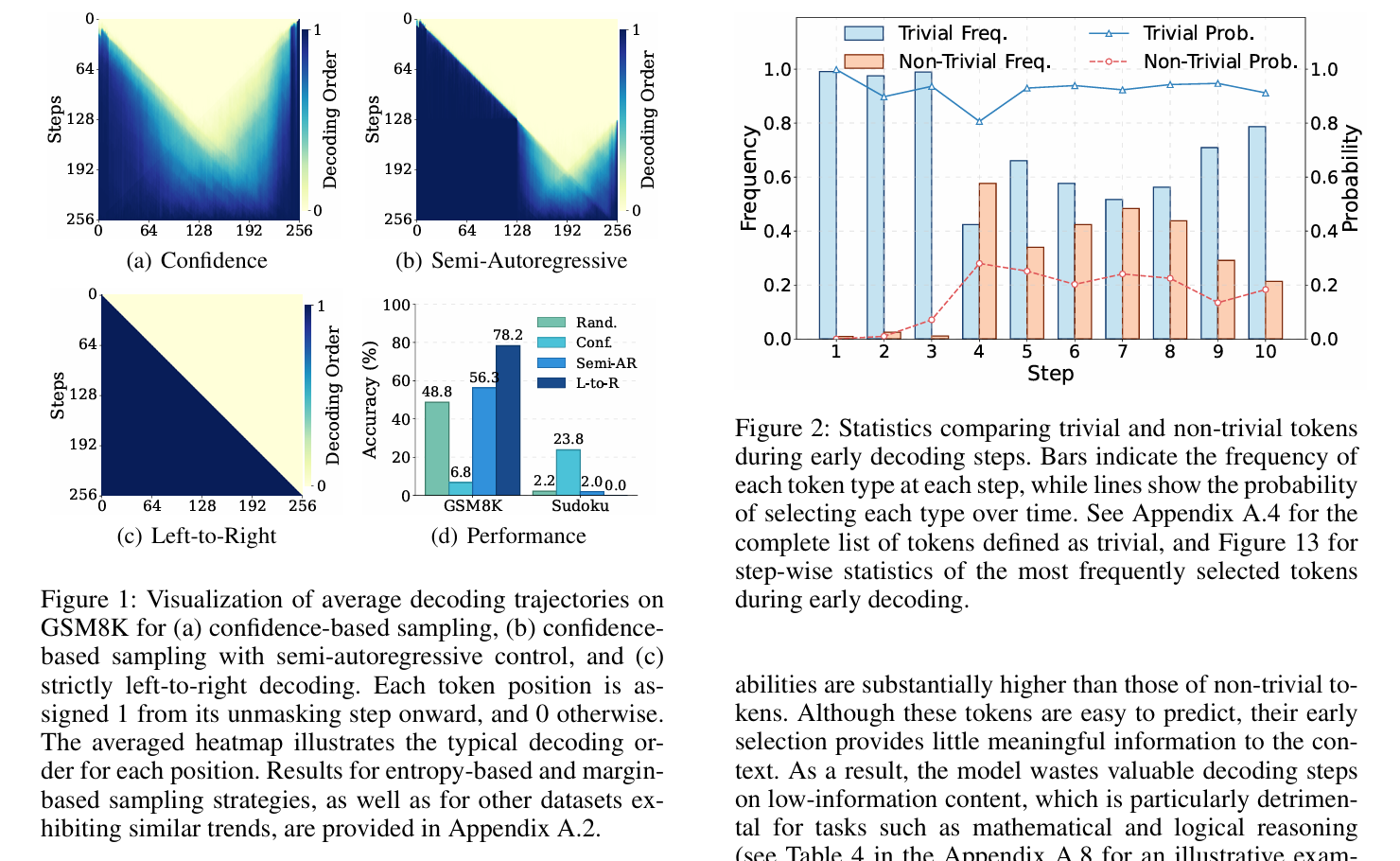
Pc-sampler: Position-aware calibration of decoding bias in masked diffusion models
Pengcheng Huang, Tianming Liu, Zhenghao Liu†, Yukun Yan, Shuo Wang, Tong Xiao, Zulong Chen, Maosong Sun
- This work discovered that mainstream uncertainty‑based decoding in Masked Diffusion Models suffers from both a lack of global trajectory control and a strong early bias toward trivial tokens, and PC‑Sampler remedies this by using a position‑aware pathway planner together with a confidence calibration mechanism to boost informativeness, delivering over 10% gains on average while significantly narrowing the performance gap with autoregressive models.
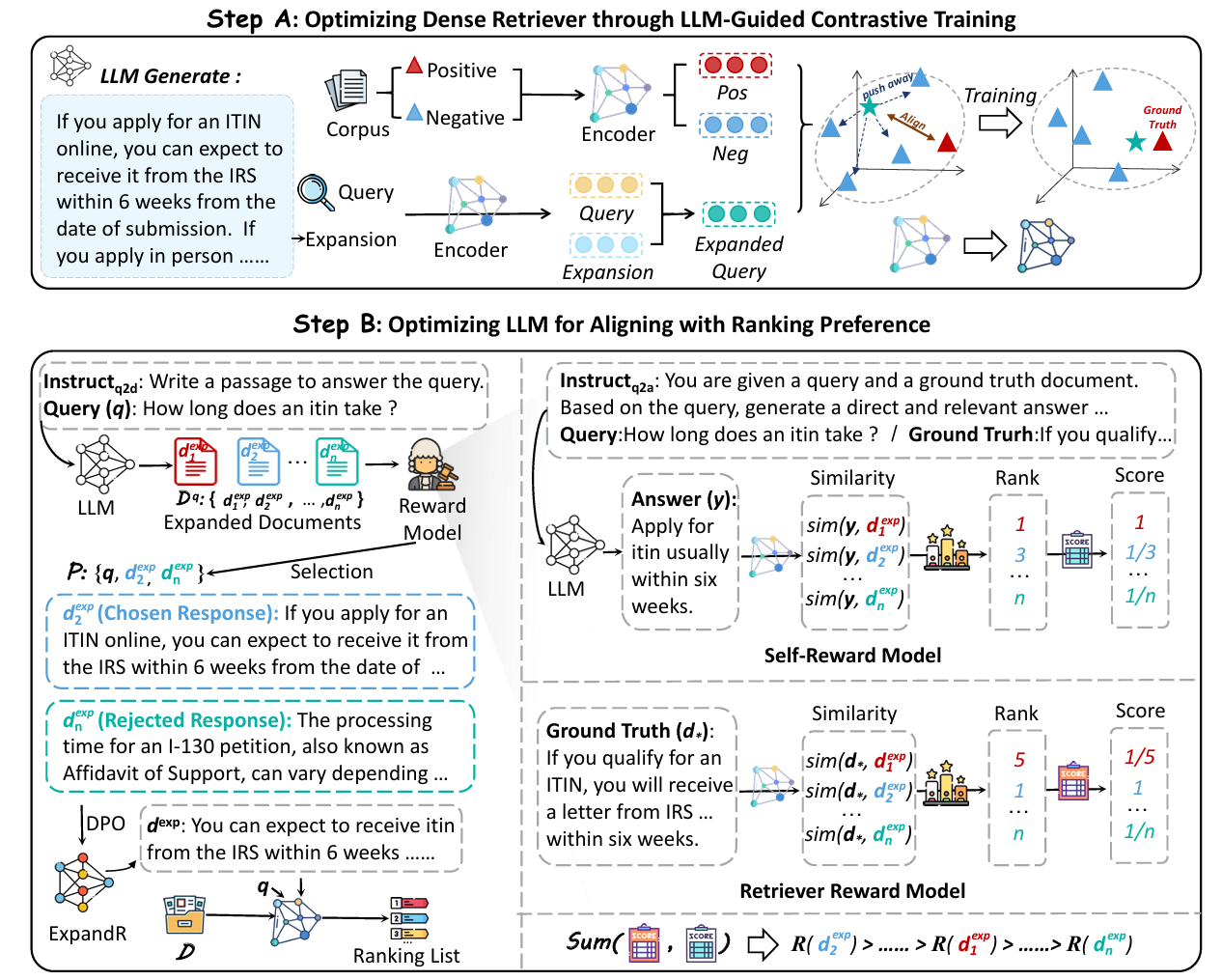
ExpandR: Teaching Dense Retrievers Beyond Queries with LLM Guidance
Sijia Yao*, Pengcheng Huang*, Zhenghao Liu†, Yu Gu, Yukun Yan, Shi Yu, Ge Yu
- This work introduces ExpandR, a unified framework that jointly trains a large language model (LLM) and a dense retriever by having the LLM generate rich query expansions and optimizing both expansion generation (via Direct Preference Optimization with combined rewards for retrieval utility and consistency) and retriever ranking performance at the same time, resulting in >5% boost over strong baselines on retrieval benchmarks.
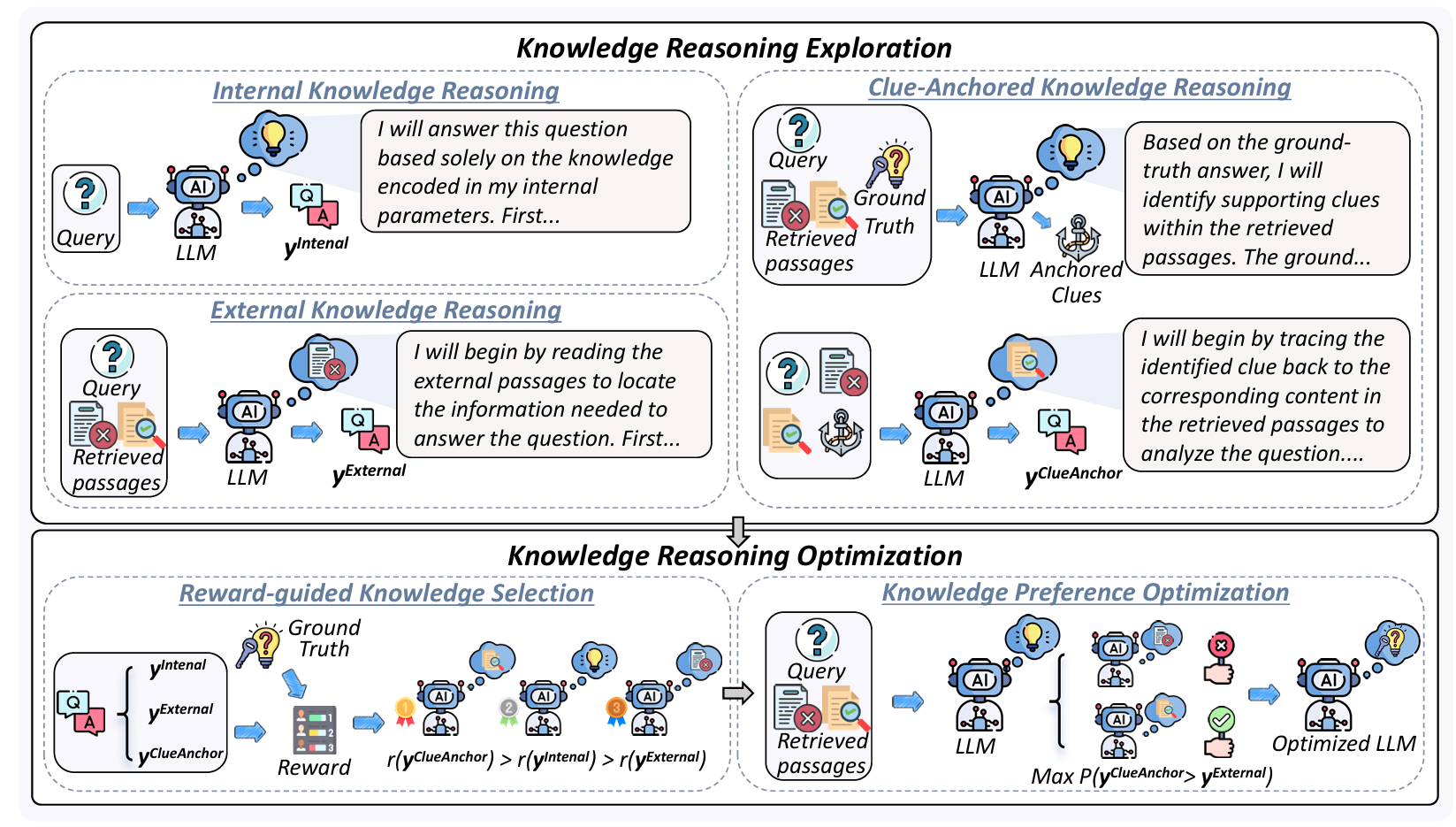
ClueAnchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation
Hao Chen, Yukun Yan, Sen Mei, Wanxiang Che, Zhenghao Liu, Qi Shi, Xinze Li, Yuchun Fan, Pengcheng Huang, Qiushi Xiong, Zhiyuan Liu, Maosong Sun
- This work discovered that RAG systems often under‐utilize retrieved documents because critical evidence (“clues”) is implicit, dispersed, or obscured by noise, and ClueAnchor addresses this by first extracting key clues from the retrieved content, generating multiple reasoning paths under different knowledge configurations (internal, external, and clue‑anchored), and then using reward‑based preference optimization to select the most effective path — yielding much better reasoning completeness and robustness.
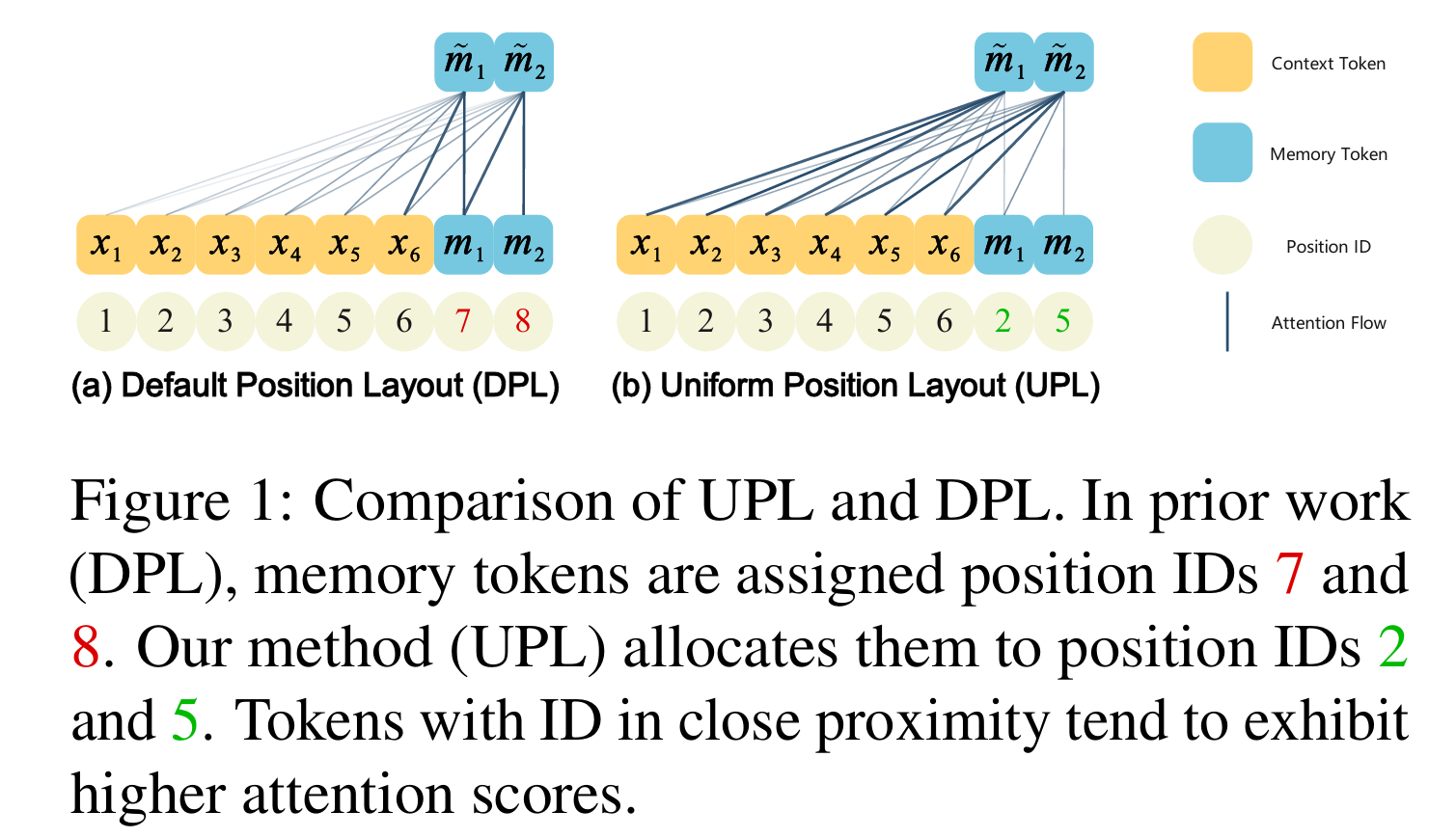
Position IDs Matter: An Enhanced Position Layout for Efficient Context Compression in Large Language Models
Runsong Zhao, Xin Liu, Xinyu Liu, Pengcheng Huang, Chunyang Xiao, Tong Xiao†, Jingbo Zhu
- This work identifies that existing LLM context‑compression methods like ICAE suffer from suboptimal position identifier layouts for compressed tokens and that the auto‑encoding loss alone insufficiently promotes memorization; it then proposes spreading position identifiers uniformly across input and introducing a “compression loss” focused purely on memorization, enabling much higher compression ratios (up to ~15× vs 4×) while retaining reconstruction and downstream performance.
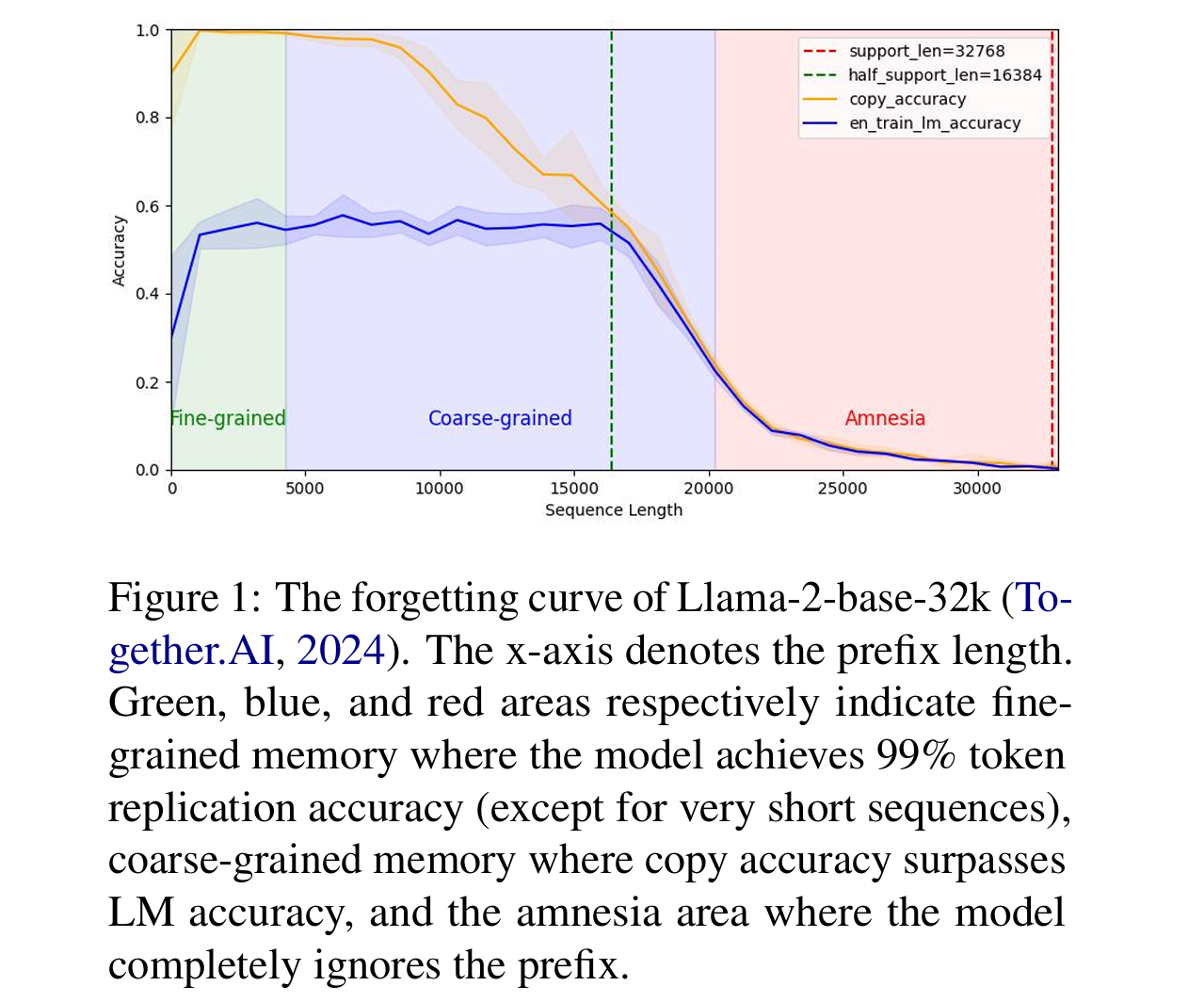
Forgetting curve: A reliable method for evaluating memorization capability for long-context models
Xinyu Liu, Runsong Zhao, Pengcheng Huang, Chunyang Xiao, Bei Li, Jingang Wang, Tong Xiao†, Jingbo Zhu
- This work discovered that existing methods for measuring memorization in long‑context models (e.g. via perplexity or “needle in a haystack” tasks) are unreliable—being overly sensitive to prompts, corpora, or downstream tasks—and proposes the Forgetting Curve, a prompt‑free, robust metric based on comparing copy accuracy vs. LM accuracy over prefixes to more faithfully capture a model’s memory over long contexts, revealing that many claimed context extension techniques may not truly improve memorization for very long inputs.
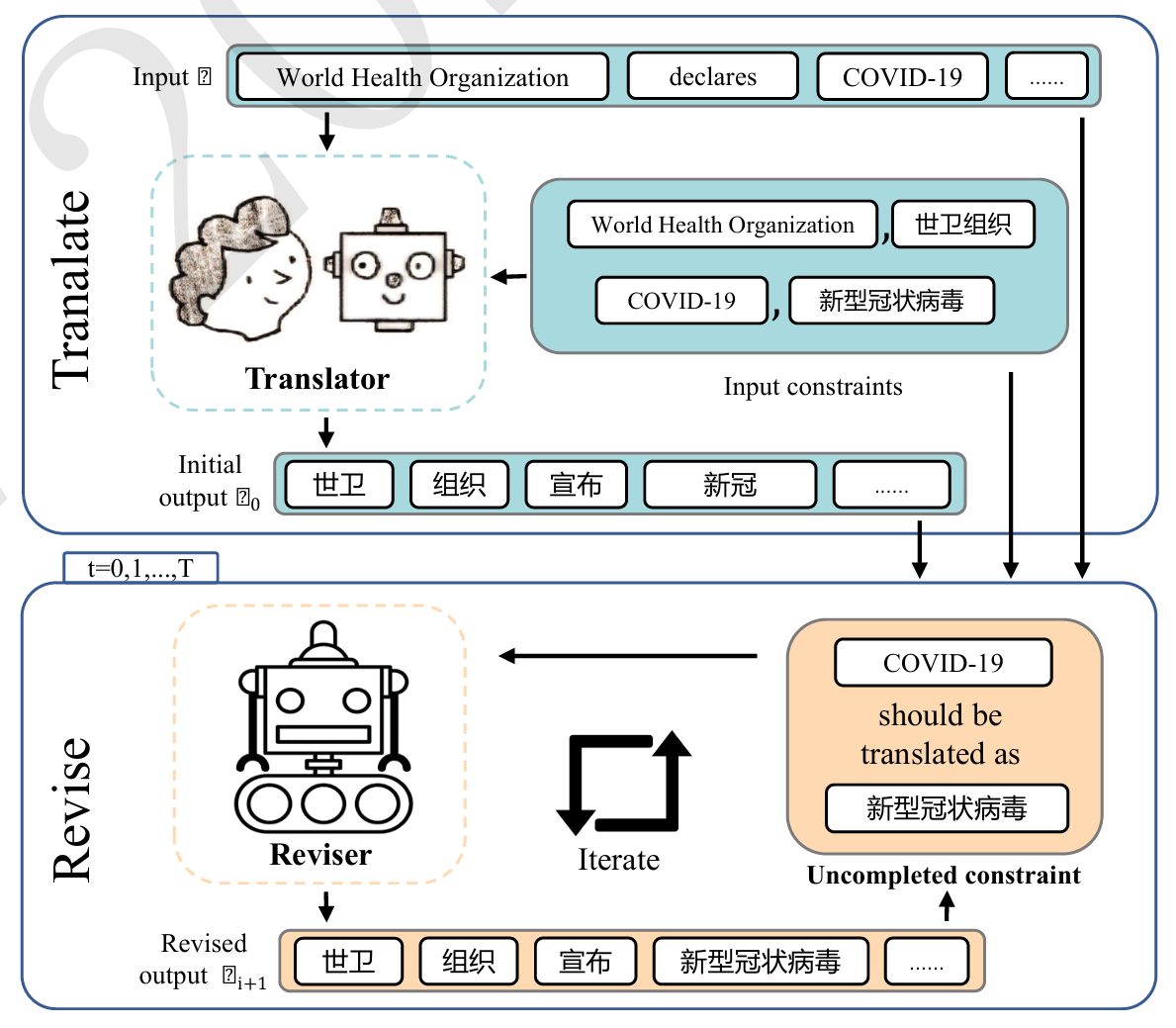
Translate-and-Revise: Boosting Large Language Models for Constrained Translation
Pengcheng Huang, Yongyu Mu, Yuzhang Wu, Bei Li, Chunyang Xiao, Tong Xiao†, Jingbo Zhu
- This work discovers that large language models (LLMs) prompted for constrained translation often ignore or violate specified lexical or structural constraints—partly because they’re overly confident and let their own fluency priorities override constraint satisfaction—and Translate‑and‑Revise remedies this by adding a revision process that prompts the model to identify unmet constraints and correct its output, yielding ~15% improvement in constraint translation accuracy and surpassing NMT baselines.
🏆 Awards
- 2024.05 🥇First Prize of Excellent Student Scholarship.
- 2023.05 🥇First Prize of Excellent Student Scholarship.
- 2022.05 🥇First Prize of Excellent Student Scholarship.
📖 Educations
- 2025.09 - now, Ph.D. School of Computer Science and Engineering, Northeastern University
- 2022.09 - 2025.07, M.S. School of Computer Science and Engineering, Northeastern University
- 2018.09 - 2022.07, B.S. School of Computer Science and Engineering, Northeastern University
💻 Internships
- 2025.3 - now, THUNLP, Beijing.
- 2024.10 - 2025.3, Language Technologies Institute (LTI), Carnegie Mellon University, Online.
- 2024.05 - 2024.09, Taobao-Tmall Search (Alibaba Group), Hangzhou.
- 2023.12 - 2024.05, ByteDance, Douyin E-commerce, Beijing.